
上周,2014Spark峰会在美国旧金山举行,与会数据库平台供应商DataStax宣布,与Spark供应商Databricks合作,在它的旗舰产品 DataStax Enterprise 4.5 (DSE)中,将Cassandra NoSQL数据库与Apache Spark开源引擎相结合,为用户提供基于内存处理的实时分析。
Databricks是一家由Apache Spark创始人成立的公司。谈到这次合作,DataStax副总裁John Glendenning表示:“将Spark与Cassandra集成,这还是数据库行业内的第一次合作。”
Cassandra是一个分布式、高可扩展的数据库,用户可以创建线上应用程序,实时处理大量数据。
Apache Spark是应用于Hadoop集群的处理引擎,在内存条件下可以为Hadoop加速100倍,在磁盘上运行时也能实现十倍的加速。Spark还提供SQL、流数据处理、机器学习和图型计算等功能。
Cassandra与Spark的结合,让端到端的分析工作流的实现更为容易。另外,交易型数据库的分析性能也能得到很大的提升,企业可以更快地响应客户需求。
对于需要向客户提供实时推荐和个性化的在线体验的公司,Cassandra与Spark的结合堪称福音。
视频分析公司的Cassandra/Spark应用先例
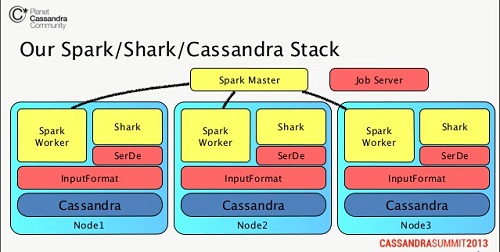
Cassandra+Spark架构的使用早有先例,Ooyala就是其中之一。Ooyala是一家视频分析供应商。Ooyala每天要处理20亿个视频事件,在大约220个节点上有约28TB的数据要处理。但是Ooyala的技术团队负责人 Harry Robertson还是能够自信地说:“我们不是仅仅告诉客户,你的视频几天播放了100遍,我们会提供更详细的信息,比如有80次播放来自于北京,20次来自于Yahoo.com。”而支撑这一切的正是Cassandra集群。
但是,只拥有大数据的处理能力还不够,Ooyala需要将“堆积如山”的原始事件转变成小的、可操作的事件。公司之前考虑过Hadoop,但Hadoop扩展性有余,实时性不足。也考虑过Storm这样的实时流处理框架,但它只有处理固定的流程时才具有优势,弹性查询能力欠佳。最终,Ooyala选择了内存分布式计算框架Spark。
现在Ooyala正在运行的就是Spark/Cassandra架构。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
数据分析是关于文化,而非技术
在新加坡,Tableau公司新数据准备工具发布会上,发言人表示,数据分析日益盛行的原因在于数据量呈指数级增长以 […]
-
攻关克难:大数据系统中的预测技术
大数据分析近年来逐渐成为预测分析技术的代名词。这使得越来越多的人以为,任何用于预测分析的系统都必定涉及大数据; […]
-
让工业无忧 天泽智云发布工业智能应用孵化器GenPro
工业世界看似离我们遥远,却与我们的福祉紧密相连。数据和智能分析赋予我们更加广阔的视野,能够以预测的方式管理和避免还未发生的问题。
-
CardinalCommerce如何满足用户日益增长的数据分析需求?
通过使用Spark进行大数据分析,Visa全资附属公司CardinalCommerce在整个组织内加大了对数据的需求,并让更多的内部用户参与分析过程。