
大堡礁位于澳大利亚东北海岸,是世界著名的水下风景区,是潜水专业人士和潜水爱好者的乐园。在50公里外的昆士兰北部海岸,我这个数据科学家正在度过为期两周的暑假,站在所租船只湿漉漉的尾部,穿着过于紧身的潜水衣,准备跨入深水区第一步。 潜水眼镜,没问题,氧气也没问题。配重腰带收紧,背心充气,没有鲨鱼在视线里,出发! 探索深海 事实证明,潜水对于爱好数据的专业人士来说是一项完美的运动,因为数据收集是潜水程序的重要组成部分。
慢慢地沉入海洋深处,你可以想象自己第一次沉入一个未经勘探的数据湖。在成千上万的生物中寻找最大的鱼或最鲜艳的珊瑚,这就像在大规模的数据集中寻找隐藏的洞察。 但深度不仅仅与深海潜水有关。作……
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
探索深海
事实证明,潜水对于爱好数据的专业人士来说是一项完美的运动,因为数据收集是潜水程序的重要组成部分。慢慢地沉入海洋深处,你可以想象自己第一次沉入一个未经勘探的数据湖。在成千上万的生物中寻找最大的鱼或最鲜艳的珊瑚,这就像在大规模的数据集中寻找隐藏的洞察。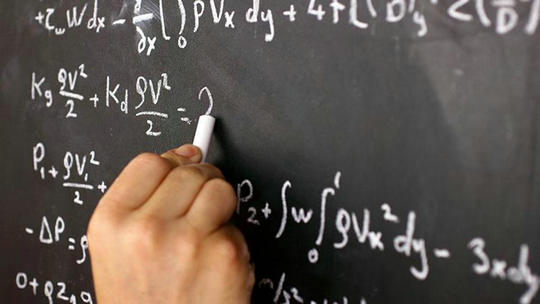 但深度不仅仅与深海潜水有关。作为一个概念,它对于数据分析和机器智能越来越重要的。人工神经网络,相互连接的处理元件的计算模型——人工神经元——松散地受到人脑的启发,并且已经存在了几十年。这些网络,历史上由一个或两个隐藏的神经元层组成,从浅层结构发展到深层结构——又叫做深度学习。这种转变是由大规模建造大型和并行模型成本的下降,以及需要训练深度模型的大数据和多维数据集的可用性的增加来支持的。
但深度不仅仅与深海潜水有关。作为一个概念,它对于数据分析和机器智能越来越重要的。人工神经网络,相互连接的处理元件的计算模型——人工神经元——松散地受到人脑的启发,并且已经存在了几十年。这些网络,历史上由一个或两个隐藏的神经元层组成,从浅层结构发展到深层结构——又叫做深度学习。这种转变是由大规模建造大型和并行模型成本的下降,以及需要训练深度模型的大数据和多维数据集的可用性的增加来支持的。
- 深度学习—机器学习的分支
- 深度学习—不是仅限技术部门
- 深度学习—一种权衡
相关推荐
-
AI就是“大数据+机器学习”?答案是否定的
人工智能(AI)应用程序不是一个单一的工具,它将各种工具和技术集合在一起从而产生更加高级的功能。
-
【对话Teradata高管】人工智能(AI)大势所趋 “黑盒” 制肘深度学习
Teradata天睿公司最近在2017 Teradata全球用户大会上分享了一项最新人工智能(AI)现状的调查结果。
-
大数据时代 成功的三重境界
当数据蜂拥而至,你看到的是机遇还是挑战?无论是对传统行业还是新型行业来说,大数据是一种手段,而不是目的,如何实现数据的价值是抢占市场先机的关键。成功,来自“数据-分析-价值”三重境界。”
-
丹斯克银行:应用人工智能和深度学习创新侦测复杂欺诈
丹斯克银行正在利用人工智能和深度学习在多个领域来侦测和预防复杂的欺诈,因为这个模式正在不断地学习,所以它的效果越来越好。