
序言
数据库和文件中储存的数据量每天都在增长,因此我们需要构建能够储存大量数据(“大数据”),并且廉价、可维护、可伸缩的环境。传统的关系数据库(RDBMS)系统在当前的需求下成本过高并且不可伸缩,因此开发、使用能够满足需求的新技术正合时宜。
在这些方向中,云计算是其中一项领先的技术。云计算有许多不同的实现,我们选择的是Hadoop,这是一个拥有Apache许可、基于Google Map Reduce的框架。
在本文中,我将尝试说明如何构建一个可伸缩的Hadoop集群,以存储、索引、检索和维护理论上无限容量的数据。
本文将逐步介绍这些部分的安装和配置:
- 网络体系结构
- 操作系统
- 硬件要求
- Hadoop软件安装/设置
网络架构
根据我们目前能够拿到的文档,可以认为云内的节点越在物理上接近,越能获得更好的性能。根据经验,网络延时越小,性能越好。
为了减少背景流量,我们为这个云创建了一个虚拟专用网。另外,还为应用服务器们创建了一个子网,作为访问云的入口点。
这个虚拟专用网的预计时延大约是1-2毫秒。这样一来,物理临近性就不再是一个问题,我们应该通过环境测试来验证这一点。
建议的网络架构:
- 专用TOR(Top of Rack)交换机
- 使用专用核心交换刀片或交换机
- 确保应用服务器“靠近”Hadoop
- 考虑使用以太网绑定
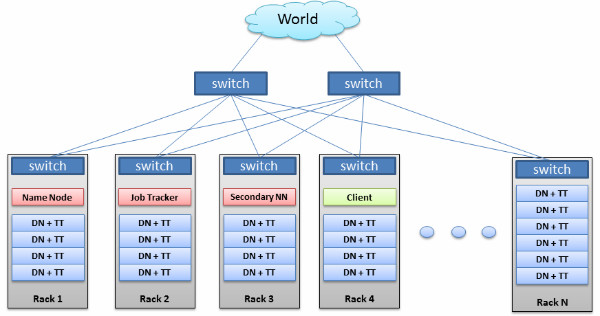
图1 – Hadoop集群的网络架构
操作系统
我们选择Linux作为操作系统。Linux有许多不同的发行版,包括Ubuntu、RedHat和CentOS等,无论选择哪一个都可以。基于支持和许可费用的考虑,我们最终选择了CentOS 5.7。最好是定制一个CentOS的映像,把那些需要的软件都预装进去,这样所有的机器可以包含相同的软件和工具,这是一个很好的做法。
根据Cloudera的建议,OS层应该采用以下设置:
- 文件系统
Ext3文件系统
取消atime
不要使用逻辑卷管理
- 利用alternatives来管理链接
- 使用配置管理系统(Yum、Permission、sudoers等)
- 减少内核交换
- 撤销一般用户访问这些云计算机的权限
- 不要使用虚拟化
- 至少需要以下Linux命令:
/etc/alternatives
ln、chmod、chown、chgrp、mount、umount、kill、rm、yum、mkdir
硬件要求
由于Hadoop集群中只有两种节点(Namenode/Jobtracker和Datanode/Tasktracker),因此集群内的硬件配置不要超过两种或三种。
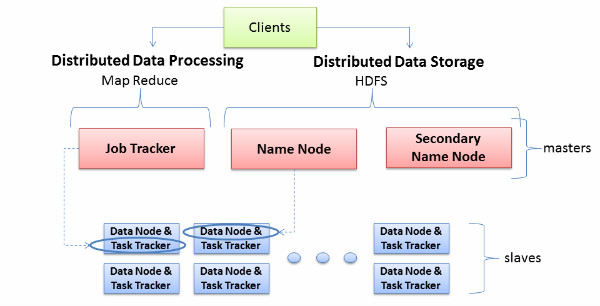
图2 – Hadoop集群服务器角色
硬件建议:
- Namenode/Jobtracker:1Gb/s以太网口x2、16GB内存、4个CPU、100GB磁盘
- Datanode:1Gb/s以太网口x2、8GB内存、4个CPU、多个磁盘,总容量500GB以上
实际的硬件配置可以与我们建议的配置不同,这取决于你们需要存储和处理的数据量。但我们强烈建议不要在集群中混用不同的硬件配置,以免那些较弱的机器成为系统的瓶颈。
Hadoop的机架感知
Hadoop有一个“机架感知”特性。管理员可以手工定义每个slave数据节点的机架号。为什么要做这么麻烦的事情?有两个原因:防止数据丢失和提高网络性能。
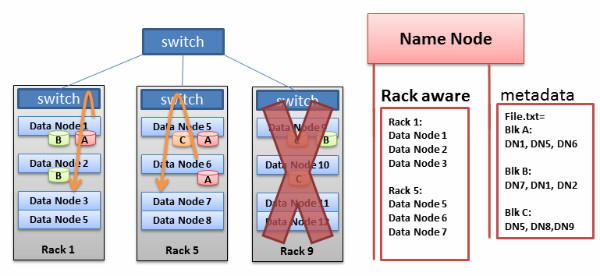
图3 – Hadoop集群的机架感知
为了防止数据丢失,Hadoop会将每个数据块复制到多个机器上。想象一下,如果某个数据块的所有拷贝都在同一个机架的不同机器上,而这个机架刚好发生故障了(交换机坏了,或者电源掉了),这得有多悲剧?为了防止出现这种情况,必须要有一个人来记住所有数据节点在网络中的位置,并且用这些知识来确定——把数据的所有拷贝们放在哪些节点上才是最明智的。这个“人”就是Name Node。
另外还有一个假设,即相比不同机架间的机器,同一个机架的机器之间有着更大的带宽和更小的延时。这是因为,机架交换机的上行带宽一般都小于下行带宽。而且,机架内的延时一般也小于跨机架的延时(但也不绝对)。
机架感知的缺点则是,我们需要手工为每个数据节点设置机架号,还要不断地更新这些信息,保证它们是正确的。要是机架交换机们能够自动向Namenode提供本机架的数据节点列表,那就太棒了。
Hadoop软件的安装和配置
Hadoop集群有多种构建方式:
- 手工下载tar文件并复制到集群中
- 利用Yum仓库
- 利用Puppet等自动化部署工具
我们不建议采用手工方式,那只适合很小的集群(4节点以下),而且会带来很多维护和排障上的问题,因为所有的变更都需要用scp或ssh的方式手工应用到所有的节点上去。
从以下方面来看,利用Puppet等部署工具是最佳的选择:
- 安装
- 配置
- 维护
- 扩展性
- 监控
- 排障
Puppet是Unix/Linux下的一个自动化管理引擎,它能基于一个集中式的配置执行增加用户、安装软件包、更新服务器配置等管理任务。我们将主要讲解如何利用Yum和Puppet来安装Hadoop。
利用Yum/Puppet搭建Hadoop集群
要利用Puppet搭建Hadoop集群,首先要符合以下前置条件:
- 包含所有必需Hadoop软件的中央仓库
- 用于Hadoop部署的Puppet装载单(manifest)
- 用于Hadoop配置管理的Puppet装载单
- 用于集群维护的框架(主要是sh或ksh脚本),以支持集群的start/stop/restart
- 利用puppet构建整个服务器(包括操作系统和其它软件)
注:如果要用Yum来安装Hadoop集群,则所有服务器应该预先构建完成,包括操作系统和其它软件都应安装完毕,yum仓库也应在所有节点上设置完毕。
构建Datanode/Tasktracker
如果用Yum安装Datanode/Tasktracker,需在所有数据节点上执行以下命令:
| yum install hadoop-0.20-datanode –y yum install hadoop-0.20-tasktracker –y |
换成Puppet的话,则是:
| class setup_datanode { if ($is_datanode == true) { make_dfs_data_dir { $hadoop_disks: } make_mapred_local_dir { $hadoop_disks: } fix_hadoop_parent_dir_perm { $hadoop_disks: } } # fix hadoop parent dir permissions define fix_hadoop_parent_dir_perm() { … } # make dfs data dir define make_dfs_data_dir() { … } # make mapred local and system dir define make_mapred_local_dir() { … } } # setup_datanode |
构建Namenode(及辅助Namenode)
如果用Yum安装Namenode,需在所有数据节点上执行以下命令:
| yum install hadoop-0.20-namenode –y yum install hadoop-0.20-secondarynamenode –y |
换成Puppet的话,则是:
| class setup_namenode { if ($is_namenode == true or $is_standby_namenode == true) { … } exec {“namenode-dfs-perm”: … } exec { “make ${nfs_namenode_dir}/dfs/name”: … } exec { “chgrp ${nfs_namenode_dir}/dfs/name”: … } if ($standby_namenode_host != “”) { … } exec { “own $nfs_standby_namenode_dir”: … } } # /standby_namenode_hadoop if ($standby_namenode_host != “”) { … } exec { “own $standby_namenode_hadoop_dir”: … } } } } class setup_secondary_namenode { if ($is_secondarynamenode == true) { … } …. } exec {“namenode-dfs-perm”: … } } } |
构建JobTracker
如果用Yum安装Jobtracker,需在所有数据节点上执行以下命令:
| yum install hadoop-0.20-jobtracker –y |
换成Puppet的话,则是使用与构建Namenode相同的装载单,唯一的区别在于,在Jobtracker机器上,会启动Jobtracker——即将该机器上的is_jobtracker设置为true。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
翻译
相关推荐
-
Cloudera-Hortonworks合并或将减少Hadoop用户的选择
近日大数据领域两家顶级供应商达成交易协议,这可能会影响Hadoop和其他开源数据处理框架,并使大数据用户的技术 […]
-
采矿设备制造商利用BI on Hadoop来挖掘数据
如果大数据要取得巨大成功,则需要提供给更多的最终用户群组。但广泛使用的商业智能工具尚不能轻松分析最大的大数据, […]
-
新Qlik Sense功能可用于云计算、AI和大数据
一年前,Qlik公司公布其长期计划,即将高级云计算、AI和大数据功能添加到其自助式BI和数据可视化软件中。现在 […]
-
Cambridge Analytica秘密收集Facebook数据表明对道德数据挖掘的需求
当有关Cambridge Analytica公司秘密收集Facebook数据的消息传出时,这暴露了一个薄弱环节 […]