
因为正在做的客户项目与传感器有关,也考虑到现在普遍关注的大数据项目,我决定写这篇文章,谈谈如何对传感器数据进行处理和分析。希望能藉此学习如何去操纵、存储、分析传感器数据本身,以及传感器数据带来的特有的挑战。
我们把传感器放置于办公室中,用来收集传感器数据。从易用性角度考虑,我们使用Tinkerforge的组件和模块。
我们使用了如下四种传感器模块:
- 声响传感器(即小型麦克风)
- 温度传感器
- 多点触控传感器(可连接至12个自制铝箔触摸板)
- 运动检测器
以上四个传感器连接到一个主模块上,与Raspberry Pi相连(Raspberry Pi是一款针对电脑业余爱好者、教师、小学生以及小型企业等用户的迷你电脑,预装Linux系统)。
我们把温度传感器放在办公室的中间位置,把运动检测器放置于到厨房和浴室的走廊上。并把声响传感器放在厨房门旁边,将触控传感器放在咖啡机、冰箱门、男性浴室门把手等处。
这样安置显然不太正式(并且你不得不等老长时间才能等到数据量变大),我们很快就遇到了一些关键问题,这些与传感器相关的问题是实际场景上通常存在的。
我们选择MongoDB作为后端数据存储,主要是考虑到在驱动这次试验的客户项目中也用了它。
通过四个传感器产生的数据,一般可以分为两类:一类是温度和声响,它们一般是一个常量数据流;一类是运动和触控传感器,它们由事件触发,通常不会按照特定的频率发生。
因为数据特征不同,我们引入了MongoDB中的两种不同的文档模型。对于第一类(流式数据),我们采用MongoDB对该类应用场景建议的模型“时间序列模型(Time Series Model)。该模型由一个集合构成,集合内包含内嵌文档。内嵌层次及每个层次子文档的个数取决于数据的时间粒度。在我们的场景里,Tinkerforge传感器的时间最小粒度是100ms,于是文档结构如下所示:
- 每小时一个文档
- 键:当前小时的时间戳、传感器类型、值
- 取值:子文档集,一小时分为60个子文档记录每分钟,一分钟再分为60个子文档记录每一秒,一秒钟再分为10个子文档记录每个100ms
{
“_id” :ObjectId(“53304fcd74fece149f175975”),
“timestamp_hour” :”ISODate(2014-03-24T16:00:00)”,
“type” : “SI”,
“values” : {
“10l” : {
“05” : {
“00” : -500,
“01” : -500,
“02” : -500,
“03” : -500,
“04” :-500,
“05” : -500,
“06” : -500,
“07” : -500,
“08” : -500,
“09” : 0
}
}
}
}
文档会在MongoDB中进行预分配,将所有数据域初始化为传感器数据取值范围之外的值。这样做是为了避免文档一直增加导致MongoDB围着磁盘团团转忙得不可开交。
第二种类型的数据(事件驱动或触发)则是存储于“桶”式文档模型中。对于每种传感器,预分配若干文档,文档中有固定个数(一个桶的大小,如100)的项用以存储值。当事件发生时,会记录到这些文档中。每个事件对应一个子文档,包含100个项的数组。子文档中包含事件的起止时间及持续时间。当第一条记录或事件写入文档时,整个文档得到一个对应于开始时间的时间戳。对于每次数据库的写操作,应用会检查当前记录是否是符合当前文档的最后一条。如果是,则设置该文档的结束时间,并将随后的写操作移向下一个文档。
{
“_id” :ObjectId(“532c1f9774fece0aa9325a13”),
“end” :ISODate(“2014-03-21T12:18:12.648Z”),
“start” :ISODate(“2014-03-21T12:16:39.047Z”),
“type” : “MD”,
“values” : [
{
“start” :ISODate(“2014-03-21T12:16:44.594Z”),
“length” : 5,
“end” :ISODate(“2014-03-21T12:16:49.801Z”)
},
{
“start” :ISODate(“2014-03-21T12:16:53.617Z”),
“length” : 5,
“end” :ISODate(“2014-03-21T12:16:59.615Z”)
},
{
“start” :ISODate(“2014-03-21T12:17:01.683Z”),
“length” : 3,
“end” :ISODate(“2014-03-21T12:17:05.147Z”)
},
{
“start” :ISODate(“2014-03-21T12:17:55.223Z”),
“length” : 5,
“end” :ISODate(“2014-03-21T12:18:00.470Z”)
},
{
“start” :ISODate(“2014-03-21T12:18:04.653Z”),
“length” : 7,
“end” :ISODate(“2014-03-21T12:18:12.648Z”)
}
]
}
以上两种文档模型代表着两种极端情况,对于传感器数据,通常会在二者间权衡。
MongoDB推崇的“时间序列”模型支持高性能写操作,在模式的一致性方面具有优势:每个文档对应一个时间的自然单元(我们案例中是一个小时),这样会使数据的管理和获取更为自然。另外,依照当前时间点写“当前”文档的逻辑,对于应用程序来讲,不需要额外去跟踪记录什么。
内嵌结构允许在不同粒度和层次上对数据进行方便地聚合——虽然你不得不接受这样一个事实,这类聚合需要在你的应用程序里“手动”进行。这是由于在这类文档模型中没有对“分”、“秒”和“毫秒”的建立键。而是每个时间点,无论是分、秒、毫秒都有自己的键。
该类模型对于稀疏数据的存储,会存在一些问题。对于运动和多点触控传感器来讲,它们的数据对于该模型就有问题:由于事件可以在任何时候发生,此类数据并无任何自然频率。对于时间序列文档模型,这就意味着文档的特定域将永远不会被访问,这显然是对磁盘空间的极大浪费。
对于并非是事件驱动的传感器,也有可能产生稀疏数据。换句话说,许多传感器,虽然他们以特定的频率去测量,如果测量值跟上次测量相比发生改变才会自动输出数据。这是一个不得不面临的挑战。如果有人仍坚持使用时间序列文档模型,那么他将不得不定时检查传感器提交的数据,并把上次传感器提交的数据更新到数据库的对应槽中。当然,这样会引入大量的冗余数据到数据库中。
通过只是将实际记录的数据填写到文档中,桶式模型可以避免以上问题,但该模型仍具有其他缺点:
如果全量数据未来需重构(包括未保存的冗余数据),这需要应用程序额外进行处理。
对于一个“桶”文档,没有一致的开始和结束时间——如果你对一个特定的时间段感兴趣,则需要查找覆盖该时间段的全部的文档。
对于“桶”的管理(跟踪当前正在使用的桶,并检查是否已满),需要由应用程序来做。
Tinkerforge的传感器支持多种语言接口的API。我们选定用Python,并在传感器的宿主——Raspberry Pi上运行这些脚本。数据写入到MongoSoup上的MongoDB实例上,前者是一个将MongoDB作为服务的解决方案。通过如下API,可以完成声响和温度传感器模块的注册:
ipcon =IPConnection() #创建IP连接
ipcon.connect(BRICKD_HOST,BRICKD_PORT) #提供主机和端口信息
# 向该连接注册以下两个模块
sound_brick =SoundIntensity(config.UID_sound_intensity, ipcon)
temperature_brick=Temperature(config.UID_temperature,ipcon)
Tinkerforge的API支持通过回调函数来自动读取来自传感器的数据。为使用该功能,需要向模块注册函数如下面代码所示:
sound_brick.set_intensity_callback_period(100)
sound_brick.register_callback(sound_brick.CALLBACK_INTENSITY,stream_handler.cb_intensity_SI)
temperature_brick.set_temperature_callback_period(100)
temperature_brick.register_callback(temperature_brick.CALLBACK_TEMPERATURE,stream_handler.cb_temperature)
这样就可以每100毫秒自动查询一次传感器,并对应地调用到函数stream_handler.cb_intensity_SI和stream_handler.cb_temperature。
这里需要了解的是为节省网络带宽,只有在传感器的测量值与上次比较发生改变时才会触发你提供的函数——这就是我们上文提到的稀疏数据。
避免以上行为的一种方式则是定制代码来按照固定频率去查询传感器。但是,正如上文提到的那样,这样会导致数据库中填充有冗余数据。另外,这样做还会增加从传感器到应用程序的网络负载。
最后,我们需要确定的是哪种模型更适合实际情况。MongoDB提供灵活的数据模型,选择哪种数据模型应该根据实际情况而定,就像是你将会遇到的读模式和写模式。
在确定使用何种文档模型前,最好考虑一下如下问题:
- 从整体来看(考虑到数据库和应用程序的性能),引入稀疏/冗余数据到数据库中,和让应用程序重构冗余数据,两种方式那个成本更高,代价更大?
- 数据的变化程度有多大?如果固定值相对较少,那么引入一定程度的冗余还是无伤大雅的。
- 是否在较大的时间范围内存在固定的频率?举例来说,如果你的数据大体上在秒级时间段内是分段常量,且每段持续长度相同,那么你可以考虑把时间粒度放大,扔掉细粒度下的冗余信息。
- 如果,从另外一个角度来讲,如果定值的持续长度变化很大,那么你基本上得考虑这种类似于事件随机发生的场景,采用“桶”式模型。
在我们的实际案例中,开始的假设是温度和声响传感器数据的差异性满足“时间序列”模型的存储,而运动和触控传感器数据更适合“桶”式模型。我们就是这样做的。
在完成初始配置和处理传感器数据的Python的脚本后,我们开始了数据收集。
使用matplotlib画图工具,以及Flask作为web服务器框架,我们搭建了一个小的web服务来可视化最近收集的数据,并把它部署到Heroku上。
我们生成了三张图。第一张是触控和运动传感器随时间变化和持续的点状图。另外两张展示了声响传感器和温度传感器一段时间内的变化。图中每一个数据点均取一秒内的平均值。
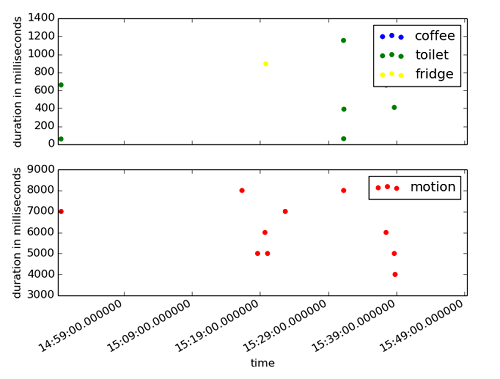
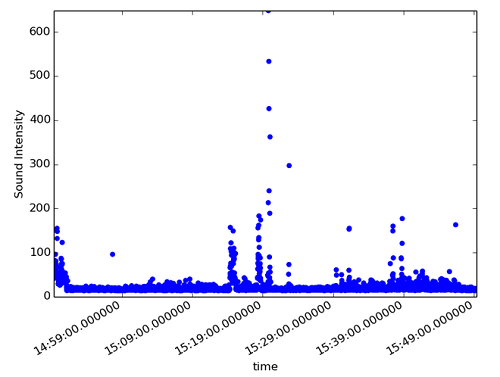
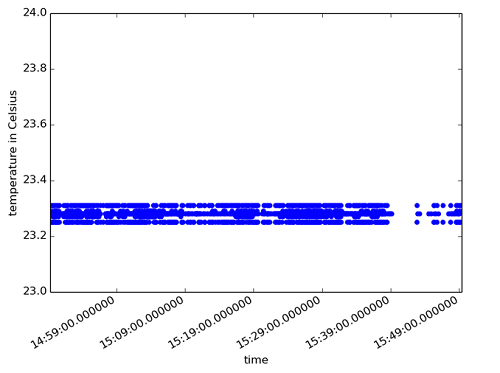
我们一眼就能看到,不同传感器受到办公室中人员活动影响产生的明显变化。
我们可以断定,对于事件性数据使用桶式模型是不错的选择,因为很可能就存在在20分钟传感器根本不记录数据的情况。
观察温度数据,明显可以看到温度的变化保持在1摄氏度范围内,虽然在这个范围内存在大幅度的波动。如果实际场景是监测一整天的温度变化,可能需要把时间粒度放大或者同时改用桶式模型。
声响数据的特点是相对较长的时间内数值很低,然后是突然、短促的脉冲事件。大家肯定不想丢失这样的信息,所以上面提到的把时间粒度放大的方法并不合适。这时,如果时间序列模型引入的冗余数据无法接受,我们可以考虑改换为桶式模型,只是在测量数据发生改变时,将数据写入数据库。
接下来,我会针对我们的数据进行统计分析和模式识别,并对数据可视化进行补充。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
学习迪士尼的分析之道
华特迪士尼公司正在继续增加对数据分析的投资,以改善其关键业务部门的客户体验。 该公司的业务包括公园和度假村、媒 […]
-
多样化数据集分析可提供最高价值
在2011年11月丰田公司推出普锐斯V后,驾驶员很快就注意到刹车时奇怪的声音。普锐斯车主在2012年4月开始致 […]
-
看烧烤店如何使用Alexa强化后厨BI指示器
Dickey连锁烧烤餐厅计划使用亚马逊的Alexa,这样加盟商就可以在烹饪时获得操作数据,在烤架外查看指示器内容。
-
用数据讲故事的黄金时代 数据人才不可或缺
我们正处在讲述数据故事的黄金时代,在您的组织中的某处,可能就有数据故事讲述者正等待着为您揭开下一次重大发现。