
【编者按】DataX是一个在异构的数据库/文件系统之间高速交换数据的工具,实现了在任意的数据处理系统(RDBMS/Hdfs/Local filesystem)之间的数据交换,由淘宝数据平台部门完成。Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。同样是大数据异构环境数据同步工具,二者有什么差别呢?本文转自Dean的博客。
从接触DataX起就有一个疑问,它和Sqoop到底有什么区别,昨天部署好了DataX和Sqoop,就可以对两者进行更深入的了解了。
两者从原理上看有点相似,都是解决异构环境的数据交换问题,都支持oracle,mysql,hdfs,hive的互相交换,对于不同数据库的支持都是插件式的,对于新增的数据源类型,只要新开发一个插件就好了,
但是只细看两者的架构图,很快就会发现明显的不同
DataX架构图
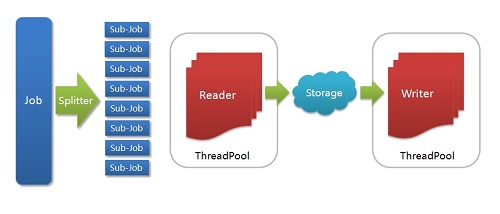
- Job: 一道数据同步作业
- Splitter: 作业切分模块,将一个大任务与分解成多个可以并发的小任务.
- Sub-job: 数据同步作业切分后的小任务
- Reader(Loader): 数据读入模块,负责运行切分后的小任务,将数据从源头装载入DataX
- Storage: Reader和Writer通过Storage交换数据
- Writer(Dumper): 数据写出模块,负责将数据从DataX导入至目的数据地
Sqoop架构图
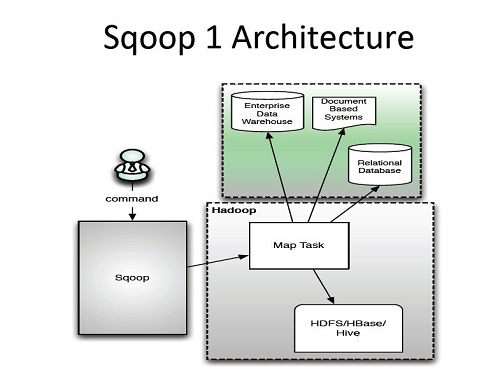
DataX 直接在运行DataX的机器上进行数据的抽取及加载。
而Sqoop充分里面了map-reduce的计算框架。Sqoop根据输入条件,生成一个map-reduce的作业,在Hadoop的框架中运行。
从理论上讲,用map-reduce框架同时在多个节点上进行import应该会比从单节点上运行多个并行导入效率高。而实际的测试中也是如此,测试一个Oracle to hdfs的作业,DataX上只能看到运行DataX上的机器的数据库连接,而Sqoop运行时,4台task-tracker全部产生一个数据库连接。调起的Sqoop作业的机器也会产生一个数据库连接,应为需要读取数据表的一些元数据信息,数据量等,做分区。
Sqoop现在作为Apache的顶级项目,如果要我从DataX和Sqoop中间选择的话,我想我还是会选择Sqoop。而且Sqoop还有很多第三方的插件。早上使用了Quest开发的OraOop插件,确实像quest说的一样,速度有着大幅的提升,Quest在数据库方面的经验,确实比旁人深厚。

在我的测试环境上,一台只有700m内存的,IO低下的oracle数据库,百兆的网络,使用Quest的Sqoop插件在4个并行度的情况下,导出到HDFS速度有5MB/s ,这已经让我很满意了。相比使用原生Sqoop的2.8MB/s快了将近一倍,sqoop又比DataX的760KB/s快了两倍。
另外一点Sqoop采用命令行的方式调用,比如容易与我们的现有的调度监控方案相结合,DataX采用xml 配置文件的方式,在开发运维上还是有点不方便。
附图1.Sqoop with Quest oracle connector
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
Cloudera-Hortonworks合并或将减少Hadoop用户的选择
近日大数据领域两家顶级供应商达成交易协议,这可能会影响Hadoop和其他开源数据处理框架,并使大数据用户的技术 […]
-
采矿设备制造商利用BI on Hadoop来挖掘数据
如果大数据要取得巨大成功,则需要提供给更多的最终用户群组。但广泛使用的商业智能工具尚不能轻松分析最大的大数据, […]
-
新Qlik Sense功能可用于云计算、AI和大数据
一年前,Qlik公司公布其长期计划,即将高级云计算、AI和大数据功能添加到其自助式BI和数据可视化软件中。现在 […]
-
Cambridge Analytica秘密收集Facebook数据表明对道德数据挖掘的需求
当有关Cambridge Analytica公司秘密收集Facebook数据的消息传出时,这暴露了一个薄弱环节 […]