
对于产品经理来讲,了解产品的使用情况是最为重要的事情之一。不过,对于Hadoop平台这样的产品来讲这件事情就有点飘忽不定了。Hadoop平台上有各种各样的运维度量对任务状态、错误、计算资源、存储等进行测量,从而帮助用户了解平台的健康状况,进而提高用户体验。对于消费级互联网、移动互联网公司的产品经理来讲,同样的事情也是存在的。举例来说,就消费级产品来讲,它们的度量通常围绕用户活动、参与度、收入、转换率、存留率等进行的。
本文提出一些在Hadoop平台上获取用户度量的基本方法,用以进行使用模式分析;并根据分析结果进行产品规划。
Hadoop用户度量会依据使用的Hadoop发行版有所改变,这里我使用的是Cloudera公司的Hadoop发行版。Cloudera公司提供有一个不错的工具,叫Cloudera Navigator。该工具提供事件的配置、收集、查看等审计功能,从而更好的了解数据使用人员及其使用方式。对于大多数应用场景的需求该工具均能满足,使得平台的查看和审计变得容易许多。Cloudera Navigator是Cloudera Manager的一部分,后者提供了一系列的健壮的API,用来与已有的监控工具进行整合。另外,Cloudera Manager还提供了可配置的控制面板,对每个度量均能进行可视化的近实时跟踪。
ClouderaManager API使用介绍
可能会有产品经理觉得Navigator提供的功能远远不够,他们想要在控制面板上展现更多定制化的度量、以及更多更丰富的可视化功能,那么Cloudera Manager API(CMAPI)是绝佳工具。REST API提供了大量的度量,你想要的KPI都可以通过它进行聚合和汇总。正如文档中提及的,所有接入点均操作数据的一份公共集合,调用API返回的JSON对象适用于各种接口。
在下面的示例中,我们将会看到的是使用Cloudera Manager进行查询,获得一段时间内在Hadoop集群上执行YARN任务的用户状态。使用Python脚本来展示是如何调用API的,包括传入时间段参数以及获得指定数量的JSON格式的结果。
注:本文使用Python 2.7版本。
我们来看一下接入点‘yarnApplication’——调用该接口将返回用户运行的YARN容器的属性。主要包括应用程序ID、应用程序名称、启动时间、结束时间、用户名、资源池(应用程序提交到的资源池)以及其他属性均可以通过该API获得。举例来讲,创建一个名为“yarnmetrics.py”的文件,打开该文件并输入以下内容:
1)导入必需的库
import json
import sys
importurllib2
fromdatetime import datetime, timedelta
2) 设置要返回的记录数,单个调用的记录数最大值默认为1000。
3) 我们还要把需要提取的时间分片提供给API。举例来说,可以根据当前时间取一个偏移量来设定时间分片的范围。在这个例子中,我希望API返回的是从上午九点到下午五点的数据。
cur_time =(datetime.now() – timedelta(day = 1))
to_time =cur_time.replace(hour = 17, minute = 00, second = 00, microsecond =0).isoformat()
from_time =yes_time.replace(hour = 8, minute = 0, second = 0, microsecond = 0).isoformat()
4) 将参数传入到该脚本中。我们传入的参数来告诉脚本使用哪一个API接入点进行调用。
limiter =20
metric =sys.argv[1]
5) API的接入点格式为:/api/v7/clusters/{clusterName}/services/{serviceName}/yarnApplications
该调用依赖于你集群上Cloudera Manager的具体配置。点击了解更多关于服务和角色度量的信息。
此处,我们假设一个场景:如果传入“applications”则执行下面的调用。from_time、to_time应当是ISO格式的时间戳,包括limiter在内,三个参数均需传入
6)根据Cloudera Manager安装配置的不同,你需要与它的服务器进行认证。所以我们使用base64进行编码。注:由于安全环境及配置的不同,会有不同的方式进行认证。出于演示目的,简洁起见提供以下示例:
return”Basic ” + (user + “:” +password).encode(“base64”).rstrip()
7)现在,我们可以进行API调用了,调用的请求中包括编码后的数据。
8)提交请求,并将结果输出到JSON文件中。
req =urllib2.Request(url)
req.add_header(‘Accept’,’application/json’)
req.add_header(‘Authorization’,’Basic fsfadgibberishsdfdfsfF=’) #用编码后的用户数据进行填充
9)这个时候,我们就能够获得包含特定时间段运行的全部任务的信息的JSON文件了。
你可以通过以下命令运行该脚本:python yarnmetrics.py applications
有了这些数据,便可以根据自己喜好选择可视化工具进行数据分析了。
举例来讲,你可以通过impalaQueries接口得到访问Impala数据库的用户列表。
或者通过上面提到的YARN的接口来获得日常使用情况。
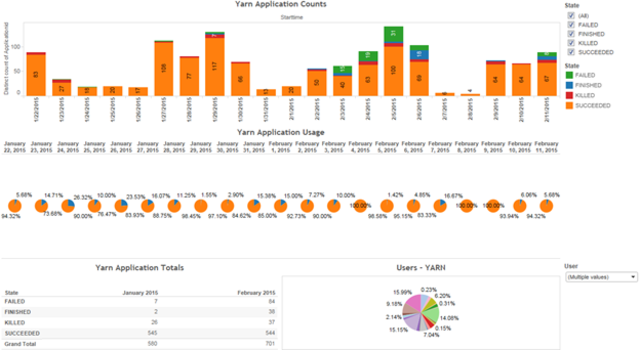
这时,也就不难使用Oozie或者Cron这样的工具进行自动化处理,从而获得任意时间间隔下的集群使用情况了。如果你还需要自动化的控制面板或者用户相关的查询,将这些结构化的JSON数据写入到Hadoop上也是可以的。一个简单的工作流就可以把这些JSON文件写入到Hive表中,然后就可以使用可视化工具访问Hive做进一步的控制面板了。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
翻译
相关推荐
-
Cloudera-Hortonworks合并或将减少Hadoop用户的选择
近日大数据领域两家顶级供应商达成交易协议,这可能会影响Hadoop和其他开源数据处理框架,并使大数据用户的技术 […]
-
数据太多Hold不住?Hadoop数据治理来“救场”
当LinkedIn还是一家规模较小的公司时,它从社交网站上获取的数据是如何被格式化和结构化的,似乎并没有人关注。
-
将数据治理工具渗透到企业中有多难?
对于主流大数据用户来说,数据治理是一个大问题。最近,IT供应商已经宣称使用开源以及商业数据治理工具来管理基于Hadoop的数据湖中的数据。
-
遇到Hadoop性能问题很头疼?监控集群很重要
大数据系统中,数据并非唯一需要管理的内容。数据科学家和其他用户所运行的查询也必须进行监控,以确保他们不会在Hadoop和Spark集群中陷入困境。