
通过Map/Reduce进行批处理递送到Apache Hadoop仍然是中枢环节。,但随着要从“超思维速度“分析方面获取竞争优势的压力递增,因此Hadoop(分布式文件系统)自身经历重大的发展。科技的发展允许实时查询,如Apache Drill, Cloudera Impala和Stinger Initiative正脱颖而出,新一代的资源管理Apache YARN 支持这些。
为了支持这种日渐强调实时性操作,我们正发布一个新MySQL Applier for Hadoop(用于Hadoop的MySQL Applier)组件。它能够把MySQL中变化的事务复制到Hadoop / Hive / HDFS。Applier 组件补充现有基于批处理Apache Sqoop的连接性。
这个组件(MySQL Applier for Hadoop)的复制是通过连接MySQL主服务,一旦二进制日志被提交,就读取二进制日志事务,并且把它们写到HDFS.
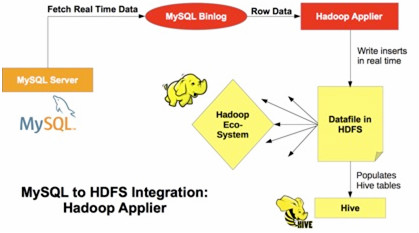
这个组件使用libhdfs提供的API,一个C库操作HDFS中的文件。这库由Hadoop版本预编译生成的。
它连接MySQL主服务读二进制日志,然后:
- 提取发生在主服务上的行插入事件
- 解码事件,提取插入到行的每个字段的数据,并使用满意的处理程序得到被要求的格式数据。
- 把它追加到HDFS 中一个文本文件。
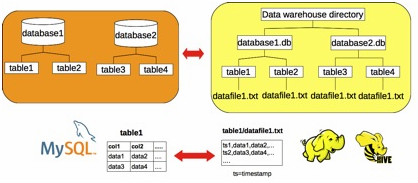
数据库被映射为单独的目录,它们的表映射为子目录,保存在数据仓库目录。每个表的数据被写到Hive/ HDFS中文本文件(称为datafile1.txt)。数据可以用逗号格式分隔;或其他格式,那可用命令行参数来配置的。
从这个blog可以了解更多有关该组设计信息。
在这个blog已经详细讨论安装,配置,实施信息。与Hive集成也有文档。
你也可以从这个视频教程明白它的作用
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
Hadoop考虑新增对象存储,弥补分布式存储HDFS不足
Hadoop社区今日提议为Hadoop增加一个新的对象存储环境,这样Hadoop就能以与亚马逊S3、微软Azure以及OpenStack Swift等云存储服务一样的方式去存储数据。
-
Hadoop 2集中式的缓存管理原理与代码剖析
Hadoop 2.3.0已经发布了,其中最大的亮点就是集中式的缓存管理。这个功能对于提升Hadoop系统和上层应用的执行效率与实时性有很大帮助
-
分析师给出关于Hadoop的12个事实
分析师Philip Russom发表了“关于Hadoop的12点事实”的主题演讲,TechTarget编辑在本文中将对其精华内容进行总结,希望对您进一步了解Hadoop有所帮助。