
随着大数据概念的崛起,Splunk成为这一波浪潮中发展最快的公司之一。Splunk的专长是在机器生成数据以及日志管理方面,他们认为高质量的决策通常都是从机器生成的琐碎日志文件数据中获得的。因此作为数据管理人员,这篇对Splunk工具的简单介绍对你应该很有帮助。
Splunk是一个托管的日志文件管理工具,它的主要功能包括:
· 日志聚合功能
· 搜索功能
· 提取意义
· 对结果进行分组,联合,拆分和格式化
· 可视化功能
· 电子邮件提醒功能
架构
Splunk的工作原理是什么?先对服务器进行配置,然后通过rsyslog向集中的Splunk服务器集群提交特定的日志声明。或者,也可以使用SFTP或NFS等。本文不具体介绍工具的安装步骤,我们主要介绍它能做哪些事情。
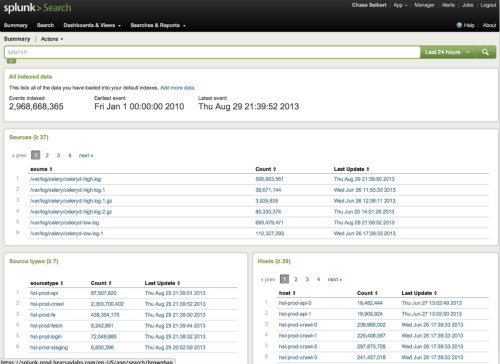
主机与源
首先注意的是,日志文件分散在在主机和随机的源中。这表示你可以从一台机器或一组机器中快速搜索出所有的日志。
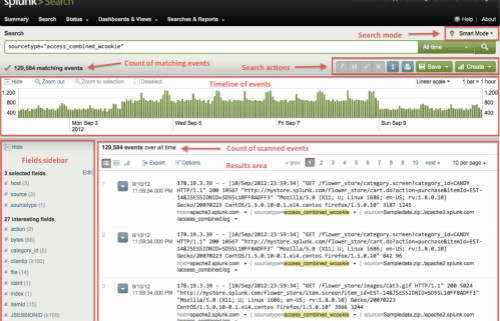
搜索
搜索功能设定的非常简单,只需输入你想要搜索的字符串,或者可以使用以下语句来进行高级搜索:
· sourcetype=”hsl-prod-fe” “Chase Seibert”
· sourcetype=”hsl-prod-fe” e186f85c914261eec9e54d3767fdd3cc BEGIN
· sourcetype=”hsl-prod-crawl” |regex _raw=”fanmgmt.(analytics|metrics)”
· sourcetype=”hsl-prod-crawl” facebook OR twitter NOT linkedin
· sourcetype=”hsl-prod-crawl” facebook OR linkedin OR twitter earliest=-24h
抽取
你可以使用内置的GUI来定义一个正则表达式,从每一行中抽取变量,可以对其进行过滤,分组和聚合操作。
如果变更日志格式,你可以通过将键值对变成key=value格式,不用定义正则表达式。以下为示例:
def key_value(prefix, log_level=’info’, **kwargs):
log_message = ‘%s: %s’ % (
prefix, ‘ ‘.join([‘%s=”%s”‘ % (k, v) for k, v in kwargs.items()]))
getattr(logging, log_level)(log_message.strip())
Piping
同Unix类似,你可以将多个命令组合起来生成更复杂的查询。比如sourcetype=”hsl-prod-crawl” succeeded |stats count perc95(task_seconds) by python_module |sort count desc |head 10.
其他命令包括:
· | uniq
· | script python myscript myarg1 myarg2
· | bucket _time span=5m
· | eval name=coalesce(firstName, lastName)
· | rare, | anomalous
· | spath output=commit_author path=commits.author.name # extract xml/json values
其他可以调用的函数包括:
· avg()
· | eval description=case(error == 404, “Not found”, error == 200, “OK”)
· floor(), ceiling()
· len()
· isbool(), isint(), etc
· upper(), lower()
· trim(), ltrim(), rtrim()
· md5()
· now()
· random()
· replace()
· split()
· substr()
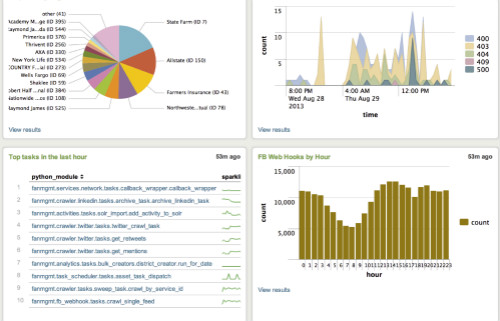
可视化功能
通过GUI builder点击就可以创建可视化图表,还可以通过命令行和函数来创建。包括饼图,柱状图,行列图以及计量图等其他复杂的图表。
邮件提醒
你可以对Splunk进行设定,根据不同的事件来触发邮件提。更多关于Splunk的使用方法,可以参考官方文档以及论坛。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
Cloudera-Hortonworks合并或将减少Hadoop用户的选择
近日大数据领域两家顶级供应商达成交易协议,这可能会影响Hadoop和其他开源数据处理框架,并使大数据用户的技术 […]
-
采矿设备制造商利用BI on Hadoop来挖掘数据
如果大数据要取得巨大成功,则需要提供给更多的最终用户群组。但广泛使用的商业智能工具尚不能轻松分析最大的大数据, […]
-
新Qlik Sense功能可用于云计算、AI和大数据
一年前,Qlik公司公布其长期计划,即将高级云计算、AI和大数据功能添加到其自助式BI和数据可视化软件中。现在 […]
-
Cambridge Analytica秘密收集Facebook数据表明对道德数据挖掘的需求
当有关Cambridge Analytica公司秘密收集Facebook数据的消息传出时,这暴露了一个薄弱环节 […]