
随着大数据概念的升温,Hadoop作为最具代表性的技术进入人们视野已有一段时间了。整个Hadoop生态系统也在飞速发展,几乎每一天都会衍生出新的功能或者新的工具。尽管有一些是微小的改动,比如Oozie中更完美地支持调度,或者还有一些仍在开发中,比如对NFS的支持。还有一些非常酷的特性,比如在Pig当中对CPython提供完整支持等。但在我看来,这些都不如Hadoop 2.0中的YARN更具革命性。
我们都知道,Hadoop有两个核心的组件,即HDFS(分布式文件系统)和MapReduce架构(分布式处理平台)。而YARN的出现,则使Hadoop从一个分布式处理架构蜕变为一个分布式操作系统。
用“操作系统”这个词可能会被很多网友吐槽,是不是夸张了点?这里我要引用计算机大牛Andrew S.Tanenbaum在《现代操作系统》一书中对OS的定义,它包括:
- 一个虚拟机:操作系统的作用,就是为用户提供一个扩展计算机或者虚拟机的环境,能让用户在底层硬件中更容易进行编程
- 一个资源管理器:操作系统要做的,是为处理器,内存,IO设备等提供有序的、可控的资源分配,以便各种程序进行使用。
针对第一个条件,Hadoop从一开始在1.0版本中就已经提供支持。而YARN的出现则满足了第二个条件。因此在我看来,Hadoop现在已经可以被视为分布式的操作系统。
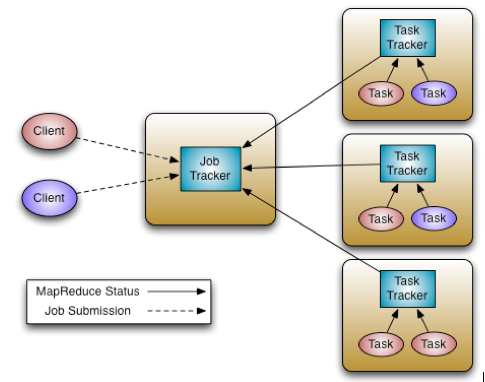
YARN就是Hadoop的资源管理器。之前的Hadoop是在MapReduce基础上构建的,虽然在计算范式上有过很多尝试,但它依然没有脱离MapReduce提供的框架。它以JobTracker和TaskTracker的形式来处理工作负载并管理服务器资源,每个节点都是配置了map和reduce。
在Hadoop 2.0中,MapReduce已经不再是唯一的选择。它提供了更好,更灵活的设计,对计算资源处理进行了分离。对于YARN,大家可以去拜读Hortonworks架构师Arun Murthy的系列文章,其中的介绍非常详细。
这里要强调一点,上文提到的计算资源处理分离已经运用到了实际的环境当中,并取得了不错的效果,比如包括:
- Storm on YARN:Twitter应用的运行在Hadoop上的流计算框架(Yahoo)
- Apache Samza:基于YARN开发的项目,可以作为Storm的替代品(Apache)
- HOYA:HBase on YARN,集群上的HBase部署工具(Hortonworks)
- Weave:基于YARN的封装,用于简化应用部署(Continuuity)
- Giraph:图形处理系统(Apache)
- Llama:让外部服务器从YARN获取资源的框架(Cloudera)
- Spark on Yarn:基于内存的分析集群技术
- Tez:通用的、高度可定制的框架,用于简化Hadoop中数据处理任务的创建,支持小规模(低延迟)和大规模(高吞吐量)负载(Hortonworks)
总之在我看来,YARN的引入对Hadoop来说是具有革命性的,是可以改变游戏规则的。而且它已经从理论走向实践,而并不是未来的某种概念。事实上,Hadoop 2.0已经正式GA了,用户已经可以直接对YARN进行测试。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
Cloudera-Hortonworks合并或将减少Hadoop用户的选择
近日大数据领域两家顶级供应商达成交易协议,这可能会影响Hadoop和其他开源数据处理框架,并使大数据用户的技术 […]
-
数据太多Hold不住?Hadoop数据治理来“救场”
当LinkedIn还是一家规模较小的公司时,它从社交网站上获取的数据是如何被格式化和结构化的,似乎并没有人关注。
-
将数据治理工具渗透到企业中有多难?
对于主流大数据用户来说,数据治理是一个大问题。最近,IT供应商已经宣称使用开源以及商业数据治理工具来管理基于Hadoop的数据湖中的数据。
-
遇到Hadoop性能问题很头疼?监控集群很重要
大数据系统中,数据并非唯一需要管理的内容。数据科学家和其他用户所运行的查询也必须进行监控,以确保他们不会在Hadoop和Spark集群中陷入困境。