
传统的行数据库使用的基本都是数据字典算法(Data Dictionary) 算法,或者叫标记化(tokenization)算法, 将Block 里面经常出现的相同值写在Block的头部,在实际储存值的地方用1,2,3,A,B 这种符号代替。这种算法将不同的列放在一起,所以出现相同值的概率非常低。 而行式数据库在每一列分开储存,可以针对每一列的特征使用不同的算法。 这篇文章就是介绍列数据库常用的压缩算法。
最早的列式数据库Sybase IQ 使用的是一种Decomposed 模型, 简单的将每一列分开,然后用rowid 来标记每一行的位置。 如下所示:
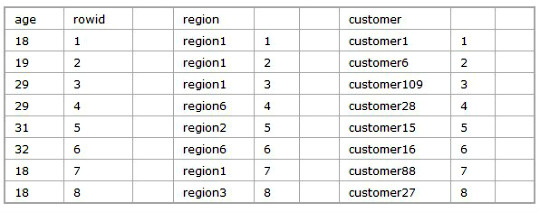
后来的列式数据库基本上都不用rowid 来标记每一列的位置, 并且对于每一个Block 的数据一定是先计算那一列具有最高选择性(唯一值最少),然后依次以选择性来排序从而可以不使用rowid 标记行的位置。
而由于排序之后相同的值在一起的机会更大,所以压缩率也就比普通的简单列储存(也即上面介绍的Decompose模型) 的压缩率大很多倍。
常见的列式数据库压缩算法有如下几种:
- Run Length Encoding (RLE)
当数据排序之后相同的值肯定在一起,并且在同一个Block 里面一个值压缩后只会出现一遍。 注意这里的排序并不是指按照值大小的排序,比如5>1 , B>A 这种,而是值将相同的值聚在一起,按出现的频率进行排序( 类似group by 之后order by 每一个字段)。 比如:
| WWWWWWWWWWWWWWBBBBBBBBBZZZZZA1 压缩后就成为 W14B9Z5A1 |
按照出现的频率进行先后顺序排序。 只要计算每一个数值出现的次数就可以计算出当前数值的起始rowid 和次数了。 这比较有利于进行in , not in , group 等sql 操作。
- BitMap Index
最原始的BitMap Index 的设计在行式数据库里面也有,大概是这样:
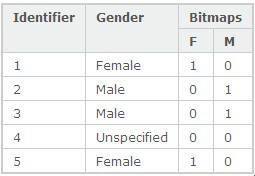
将每一个出现的值写在Block 的头部, 然后用1 和 0 来表示有或者没有。 这种算法要求每一个出现的值都必须具有非常高的选择性并且不同值之间差别不能大到几十倍的差距,而不像Run Length Encoding 只需要整体的选择性比较高就可以了。
行式数据库的BitMap Index 一般是一个整体的文件块(如果是local partition 当然也是local index)。 列式数据库的组织形式都是按每一个block 每一个block 的方式组织,它的bitmap index 出现的值都是按当前block 出现的所有值组织的。 某些列式数据库会有一些变种: 比如在1和 0 之间还加入Run length encoding 继续压缩或者加入Null Compression, 用来排除空值比较多的情况。
- Data Dictionary
行式数据库的一般都是选用的这种方式,将Block 常用的值放在block 头部, 实际出现这个值的地方用标记代替,行式数据库里面一般会有一个压缩级别的东西,压缩级别越高压缩时间越长,收益越小,解压缩时间不变。 列式数据库的Data Dictionary 压缩也是在block 的头部存放压缩之前的实际值,但是与行式数据库不同的是列式数据库会存放所有值,不管这个值即使只出现了一次,这样便于它在不可见索引和延迟物化方面可以不解压数据就能进行普通操作。
- Delta Compression
delta压缩适合在那些数据前半部分相同的情况下使用,比如很大的整数和长的有规律的字符串。 Delta 压缩会记录一个基础值,然后在之后的每一个值只使用他们差别的部分,比如电话号码,URL,地址,IP 之类的。
- LZO
LZO或者其他类似的二进制压缩算法gzip,zip,rar,7zip。bzip等等在列数据库里面也有使用,但是只适用于连读取都非常少的归档数据(每次只读非常少量的行数)和大段的文本(网页索引之类的)。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
数据分析是关于文化,而非技术
在新加坡,Tableau公司新数据准备工具发布会上,发言人表示,数据分析日益盛行的原因在于数据量呈指数级增长以 […]
-
用了多年的数据指示器软件,可能真的用错了
数据指示器软件已经存在很多年了,许多企业可能认为,现在指示器的实现是全自动的,无需人为干涉。但他们错了,这种观点可能会带来严重的问题。
-
BI和AI是两个独立的概念?是时候改变这种想法了
尽管BI和AI是两个独立的概念,但AI和BI相结合这种想法应该得到更多关注。
-
从概念到应用 一站式区分大数据和BI
IT行业的新鲜词层出不穷,最近几年,大家都在谈论大数据和BI,可是你真的明白大数据和BI之间的区别了吗?